本文共 2028 字,大约阅读时间需要 6 分钟。
随着web2.0兴起,高并发大数据量的应用对数据库快速响应的性能要求日趋明显,传统的关系型数据库在这方面显得有些乏力。有矛自有盾,内存DB的出现弥补了传统关系型db的不足。目前市面流行的内存db主要有redis、memcach、mongodb。前面二者是基于key-value形式存储,而mongodb是基于关系型数据库表的一些特性的存储方式,并支持索引。所以在一些对大数据量、数据关联度有要求的场景下,mongodb是一种不错选择。
Replica Set是mongodb的一个副本集群方案,它优越于传统的数据库主从方式。传统的主从方式,master负责读写,slaver负责从master同步数据,一旦master宕机,slaver就废了,这种方式在灾备方面有缺陷,而mongodb的Replica Set的集群机制解决了这种缺陷。
Replica Set:
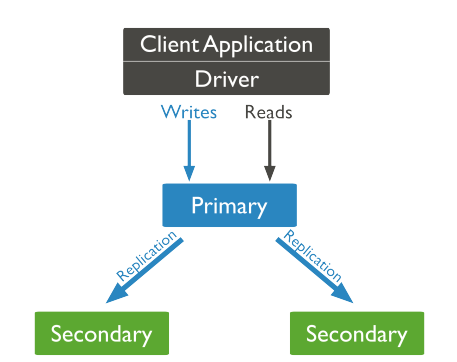
主要分为:primary(主节点,提供增删查改服务),slaver(备节点,只提供读),arbiter(仲裁节点,不存储数据,只负责仲裁)。
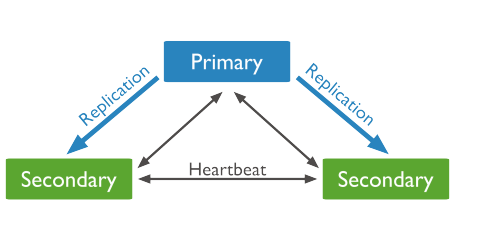
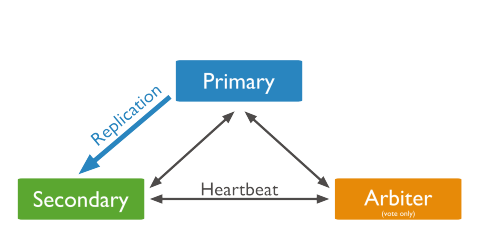
流程:client从primary节点读写数据,slaver从primary那里同步数据,当primary宕机时候,arbiter会在10秒内从众多slaver节点中选出一个健康的slaver顶替primary,这样就减轻了灾害。arbiter节点本身不存储数据,只是监测集群中primary和slaver的运行情况(如果arbiter宕机,整个集群也就废了,唯一的不足之处)。slaver只提供读的功能,不能写,我们的项目查询的需求可以去连slaver节点,这样就大大减轻了primary主节点的负载。
以下是Replica Set的流程图:
Replica Set的原理我们明白了,你可能会问,我们在编程的时候,对于primary、slaver这么多db,我们一定是往primary节点写数据,如果primary节点宕机了,程序应该怎么检测,怎么找到新的primary节点呢?
不用担心,mongodb已经解决了你的疑问。mongodb提供了对各类语言的驱动的支持,你只需调用Replica Set接口,然后参照说明来使用它,下面以node.js
var Db = require('mongodb').Db,
Server = require('mongodb').Server, ReplSet = require('mongodb').ReplSet; //集群Server地址 var serverAddr = { 9001: '192.168.1.100', //节点1 9002: '192.168.1.100', //节点2 9003: '192.168.1.100' //节点3 } //集群Sever对象的集合 var servers = []; for (var i in serverAddr) { servers.push(new Server(serverAddr[i], parseInt(i)));}
var replStat = new ReplSet(servers, {});
var db = new Db('blog', replStat);
//mongodb操作 db.open(function(err, db) { var collection = db.collection('user'); //查询一个document collection.findOne({ name: 'jerry' }, function(err, results) { console.info('query:', results); }); //插入一个document collection.insert({ name: 'ok', age: 28 }, function(err, results) { console.info('insert:' + results); });});
上面配置了几个节点9001、9002、9003,我们无需关注哪个是主节点、备节点、冲裁节点,驱动会自动判断出一个健康的主节点来给node,我们只需专心写数据库的操作逻辑就可以了。
但这里存在一个问题,Replica Set在切换节点的时候,会出现一个断档期,我们知道node是异步/O的,在这个断档期,如果node在执行大量操作的话,弱小的栈内存会溢出,报:RangeError: Maximum call stack size exceeded错误,这个错误是系统级错误,会导致app崩掉,即使捕获异常或等db切换完成,程序依然会挂死在哪里。目前还没找到解决的方法,正在研究mongo驱动的api,试图通过一个体现切换过程状态监听的事件解决,如果该事件触发,则停止db操作,待切换完成后再恢复,这样应该可以解决问题。